GenAI RAG System: Q&A Over Your Company Documents
Companies’ internal reports, policies, contracts or customer documents contain vast amounts of knowledge. However, this information often remains underutilized because employees struggle to search and retrieve the right details quickly. Large Language Models (LLMs) are powerful, but out of the box they don’t know about your company’s private documents.
Retrieval-Augmented Generation (RAG) offers a practical way to unlock this knowledge — allowing teams to ask questions in plain language and get accurate, context-aware answers directly from company documents.

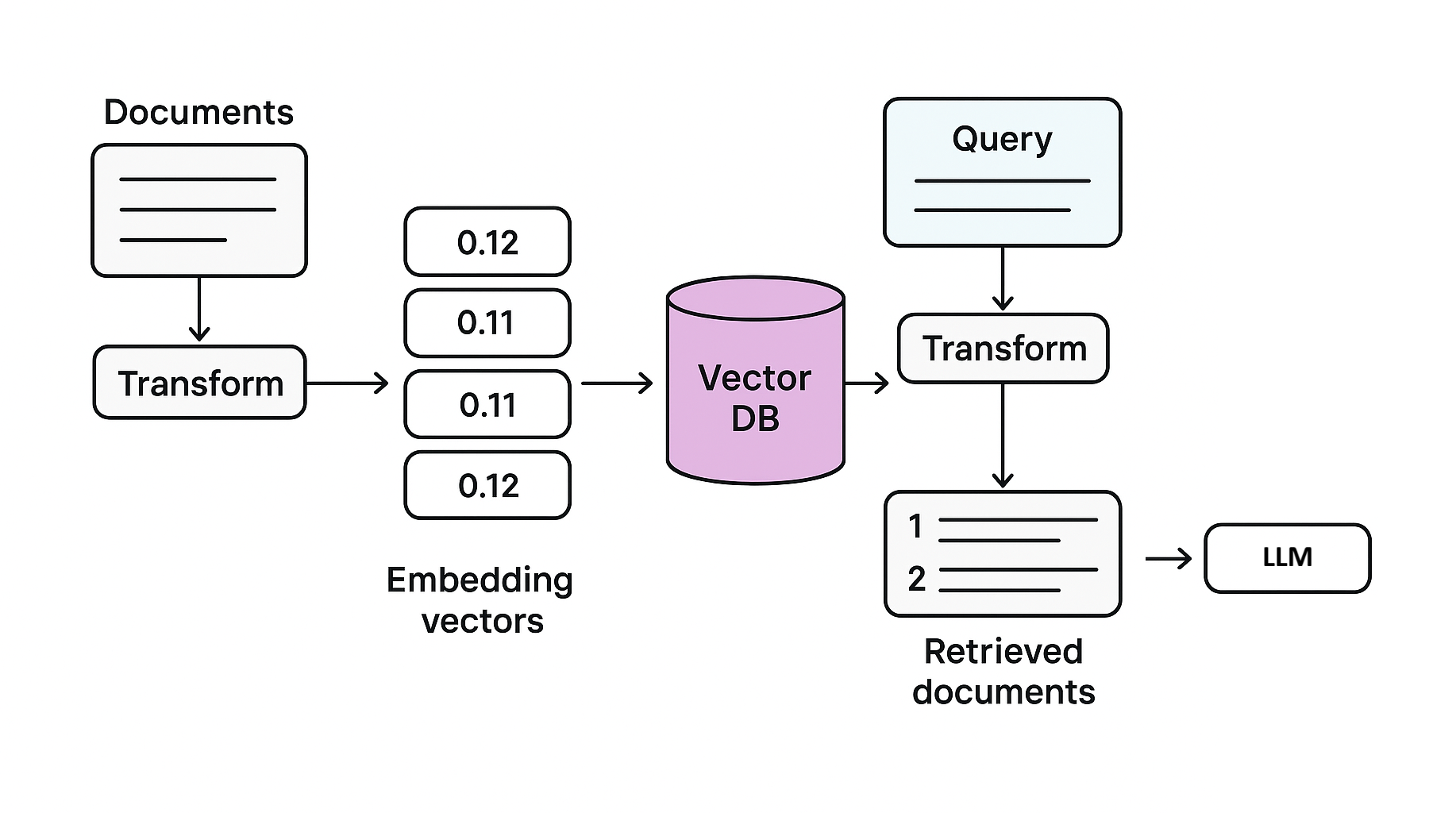
This article provides a step-by-step guide to building a simple, cost-free RAG system that runs locally, ensuring full data privacy. Using ChromaDB for document storage and SentenceTransformers for embeddings, we’ll walk through how to index custom PDF texts, perform semantic search, and integrate with a language model to generate answers tailored to specific data. The steps include:
- PDF extraction –
PyPDF2reads your PDF text. - Chunking –
RecursiveCharacterTextSplittercreates overlapping chunks for better context. - Embeddings –
SentenceTransformerturns chunks into vectors. - Vector store –
ChromaDBstores chunks + embeddings. - Retrieval + Generation –
LangChain RetrievalQAretrieves chunks and queries the LLM.
The codes in this article is tested using python 3.12, other requirements:
#requirements.txt
chromadb==1.1.0
sentence-transformers==2.6.1
protobuf==6.32.1
transformers==4.56.2
torch==2.8.0
numpy>=1.26.0
opentelemetry-exporter-otlp-proto-grpc==1.25.0
opentelemetry-sdk==1.25.0
opentelemetry-api==1.25.01. Document search engine: ChromaDB + SentenceTransformers
A vector database is a special kind of database designed to store and search vectors (arrays of numbers). In embeddings (vectors), a single word (or even a sentence, paragraph, or image) is represented by a vector, which is a list of many numbers. ChromaDB is a lightweight vector database that stores embeddings and supports fast nearest-neighbor search. It’s great for RAG because it persists vectors and metadata, allows CRUD on collections, and can return the most relevant documents or passages for a query. There are other vector databases like Milvus, FAISS, Pinecone or Weaviate.
We need to transform raw text (like PDF paragraphs) into vectors that the vector database can store and search.
SentenceTransformers is a library of transformer-based models pre-trained to produce semantically meaningful sentence embeddings (vectors). Typical models include all-MiniLM-L6-v2 (small and fast) and larger models if you want higher accuracy.
# Imports
import chromadb
from sentence_transformers import SentenceTransformer
# Create a client
client = chromadb.PersistentClient(path=".chromadb")
# Load embedding model (SentenceTransformers)
model = SentenceTransformer("all-MiniLM-L6-v2")
# Create a collection (Delete the collection if it already exists)
if "example_docs" in [c.name for c in client.list_collections()]:
client.delete_collection("example_docs")
collection = client.create_collection(name="example_docs")
# Sample texts to add to the database
documents = [
"Artificial Intelligence is transforming industries like healthcare, finance, and retail.",
"Natural Language Processing enables computers to understand and generate human language.",
"Machine learning models can predict outcomes from historical data.",
"Computer vision allows machines to analyze images and videos to detect objects and patterns.",
"ChromaDB is a vector database that stores embeddings for fast similarity search.",
"Reinforcement learning is a type of machine learning where agents learn by interacting with environments.",
"Climate change is one of the biggest challenges facing humanity today.",
"The best TV is Samsung amoung all available TV on the market"
]
# Generate embeddings
embeddings = model.encode(documents).tolist()
# Add documents + embeddings to ChromaDB collection
collection.add(
documents=documents,
embeddings=embeddings,
ids=[f"doc_{i}" for i in range(len(documents))]
)
# Ask questions (queries)
queries = [
"How can computers understand text?",
"What is reinforcement learning?",
"Which technologies help analyze images?",
"What are the biggest challenges for the environment?",
"Which is the best TV on the market?"
]
# n_results=1 returns only one answer, with lowest cosine distance.
# Thus, most relevant to the query.
for query in queries:
query_embedding = model.encode([query]).tolist()
results = collection.query(query_embeddings=query_embedding, n_results=1)
print("\n🔍 Question:", query)
for doc, score in zip(results["documents"][0], results["distances"][0]):
print(f"📜 Answer: {doc} (score: {score:.4f})")
The code returns:
🔍 Question: How can computers understand text?
📜 Answer: Natural Language Processing enables computers to understand and generate human language. (score: 0.8598)
🔍 Question: What is reinforcement learning?
📜 Answer: Reinforcement learning is a type of machine learning where agents learn by interacting with environments. (score: 0.3149)
🔍 Question: Which technologies help analyze images?
📜 Answer: Computer vision allows machines to analyze images and videos to detect objects and patterns. (score: 0.8358)
🔍 Question: What are the biggest challenges for the environment?
📜 Answer: Climate change is one of the biggest challenges facing humanity today. (score: 0.7556)
🔍 Question: Which is the best TV on the market?
📜 Answer: The best TV is Samsung amoung all available TV on the market (score: 0.3841)
Fine-tuning SentenceTransformers
In the example above, we used a pre-trained embedding model and store document embeddings in ChromaDB. It's fast to implement — no training required. And works well with small to medium datasets and many domains using robust pre-trained models.
Another option is fine-tuning of SentenceTransformers, it means training the embedding model on your own (or domain-specific) labeled sentence pairs so embeddings better reflect the similarity notion you care about.It gives better semantic matches for domain-specific language.
Combine retrieval and generation
To orchestrate the RAG process, we will use LangChain. It's an open-source orchestration framework that provides tools and components to build applications leveraging Large Language Models (LLMs). We build the Chain:
- Retrieval – "retriever" component to connect to your ChromaDB collection.
- Prompting – Create a prompt template that takes the user's question and the retrieved documents as input. The prompt should instruct the LLM to use only the provided documents to formulate an answer.
- Generation – Pass the formatted prompt to the LLM and get the final, grounded answer.
For prompting and text generation, we use GPT4All, a collection of pretrained and fine-tuned LLMs designed for local deployment. It offers ready-to-run models such as Orca, MPT, and others.
In this project, we employ the pretrained q4_0-orca-mini-3b.gguf model, which runs entirely on the local machine—no cloud API is needed—making it fast, private, and cost-free.
The final code is the following:
# Imports
import chromadb
from sentence_transformers import SentenceTransformer
from langchain.chains import RetrievalQA
from langchain_community.vectorstores import Chroma
from langchain.embeddings import SentenceTransformerEmbeddings
from langchain.llms import GPT4All
from langchain.text_splitter import RecursiveCharacterTextSplitter
import PyPDF2
# Variables - the example PDF and The LLM model path:
local_pdf_path = r"data/Newtonslaws.pdf"
gpt_model_path = r"data/q4_0-orca-mini-3b.gguf"
# Step 1: Extract text from PDF
def extract_text_from_pdf(file_path):
text = ""
with open(file_path, "rb") as f:
reader = PyPDF2.PdfReader(f)
for page in reader.pages:
page_text = page.extract_text()
if page_text:
text += page_text + "\n"
return text
pdf_text = extract_text_from_pdf(local_pdf_path)
print("PDF text extracted.")
# Step 2: Split text into chunks using RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=300, # max characters per chunk
chunk_overlap=100 # overlap for context
)
chunks = splitter.split_text(pdf_text)
print(f"Total chunks created: {len(chunks)}")
# Step 3: Initialize ChromaDB collection
client = chromadb.Client()
# Delete previous collection if exists
try:
client.delete_collection("pdf_docs")
except:
pass
collection = client.create_collection("pdf_docs")
print("ChromaDB collection ready.")
# Step 4: Embed chunks
embeddings = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
vectorstore = Chroma(
collection_name="pdf_docs",
embedding_function=embeddings,
persist_directory=".chromadb"
)
print("Chunks added to ChromaDB with embeddings.")
# Step 5: Set up Orca Mini 3B LLM
llm = GPT4All(model=gpt_model_path)
# Step 6: Build LangChain RetrievalQA
vectorstore = Chroma(
collection_name="pdf_docs",
embedding_function=embeddings,
persist_directory=".chromadb"
)
qa = RetrievalQA.from_chain_type(
llm=llm,
retriever=vectorstore.as_retriever(search_kwargs={"k":3}),
return_source_documents=False #Only one output
)
if __name__=="__main__":
# Ask a question
question = "What is Newton’s first law about?"
answer = qa.run(question)
print("🔍 Question:", question)
print("📜 Answer:", answer)
In this example, the system reads a custom PDF on Newton’s Laws (source: Wikipedia) and answers questions directly based on its content. We can further check the accuracy and see the basis for the model’s response from the document.
The example Q&A:
🔍 Question: What is Newton's first law about?
📜 Answer: Newton's first law of motion is also known as the law of inertia. It states that an object at rest will remain at rest and an object in motion will continue in motion with a constant velocity, unless acted upon by an external force.
In other words, an object will not change its state of motion unless a net force is applied to it. This law applies to all objects, regardless of their size or mass.
In summary, this example demonstrates how to develop a fully local RAG system. All frameworks used are open-source and run locally, ensuring privacy and reliability. As a next step, the system can be wrapped in a web application to provide a more convenient and user-friendly experience.